

Специалисты корпорации Google наконец-то усовершенствовали капчу, избавив пользователя от надобности вводить слова и выполнять другие непонятные действия. Отныне технология распознавания ботов способна самостоятельно определить, человек перед ней или нет. «Лента.ру» разобралась, как начиналась война с машинами и кто в ней одерживает победу.
Новая надежда
Капча (CAPTCHA — Completely Automated Public Turing test to tell Computers and Humans Apart) — это автоматизированный публичный тест Тьюринга, направленный на выявление компьютеров среди посетителей сайтов. Этот механизм защиты должен оградить сайты от спама, автоматических регистраций, накруток и прочих нелицеприятных дел, которыми обычно занимаются боты.
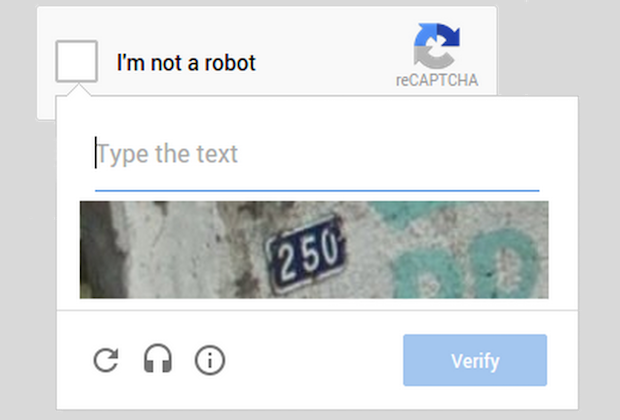
Классическая капча заключается в необходимости расшифровать сильно искаженный текст, трудно распознаваемый программными алгоритмами. Технология Google с говорящим названием No CAPTCHA отходит от стандартной концепции автоматизированного теста Тьюринга и оценивает поведение пользователя в сети, а не его способность разгадывания слов.
Пользователю нужно выполнить простейшее действие — отметить галочкой утверждение «Я не робот». В этот момент специальный скрипт оценивает косвенные параметры, указывающие на возможного бота: информация о времени, проведенном на странице, IP-адрес и прочее. Если же у No CAPTCHA закрадываются сомнения в том, что пользователь — человек, то она предложит выполнить простое задание, вроде поиска определенного объекта на картинках или ввода стандартной капчи.
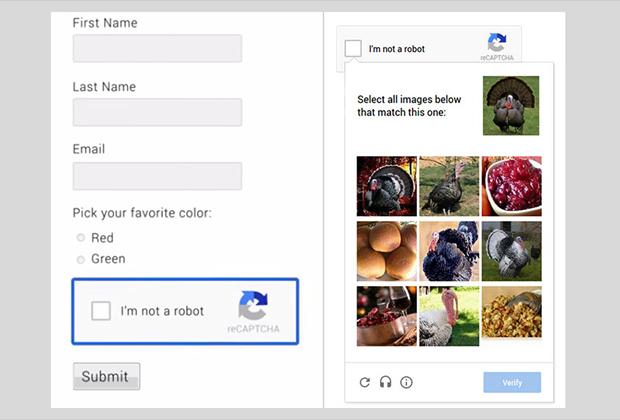
При прохождении No CAPTCHA пользователю нужно лишь поставить галочку
По сравнению с классической системой, даже нынешнее исполнение No CAPTCHA не особо обременяет пользователей. А усовершенствованная технология даже не требует ставить галочек. При проверке на экране откроется маленькое окно, в котором галочка ставится автоматически, сообщая пользователю о том, что он все-таки не робот. Если же система не уверена в этом, она запустит такой же механизм проверки, что и ранее.
Рассказывая о No CAPTCHA, разработчики ограничиваются лишь ссылками на машинное обучение и продвинутый анализ рисков, адаптируемый к новым угрозам. И их можно понять: не зная принципа работы системы, взломщики не смогут ее обойти.
Рождение легенды
Оригинальная версия капчи была разработана в 2000 году специалистами американского университета Карнеги — Меллон. Команда под руководством Луиса Фон Ана (Luis von Ahn) поставила перед собой цель создать защиту, устойчивую к распознанию и угадыванию. Это значит, что капча должна быть нерешаемой для систем распознавания текстов и прочих алгоритмов, а также ее нельзя угадать за малое число попыток (менее 1000). Но для человека она не представляет никакой трудности.
Один из первых и простейших способов обхода защиты — обратиться к обычному пользователю. Спамеры просто платили, причем смешные деньги — цент за картинку, но в бедных странах и это немало. Но в целом система была эффективна, и разработчики озадачились уже совсем другой проблемой.
Создатели капчи понимали, что на решение загадок с зашифрованным текстом миллионы пользователей тратят уйму времени, и было бы неплохо направить эти ресурсы в полезное русло. Так в 2007 году появилась reCAPTCHA, совмещающая, что называется, приятное с полезным. Ключевая ее особенность — то, что система не только защищает сайты от ботов, но и выполняет функцию расшифровки архивных документов.

Сервис reCAPTCHA предлагает пользователям помочь в расшифровке книг
ReCAPTCHA предлагает ввести пользователю не одно, а два слова, что довольно редко встречается в других системах. Секрет в том, что одно слово уже известно системе, и именно по нему будет проходить проверка, а второе взято из отсканированного документа, не расшифровываемого алгоритмом. Таким образом при прохождении теста пользователь помогает расшифровать реальный текст из старого документа. Конечно же, никто ему за это не заплатит, да и знали о такой уловке немногие.
Когда с помощью reCAPTCHA были расшифрованы архивные номера газеты The New York Times, на авторов этой системы обратили внимание в Google. В итоге «корпорация добра» купила сервис (в 2009 году) и взялась за расшифровку старых книг, а потом и за распознавание фрагментов снимков из Google Street View. Благодаря сервису в день оцифровывалось примерно 100 миллионов слов, что давало более двух миллионов книг в год.
Помимо reCAPTCHA, есть множество других вариантов. Умельцы со всего мира создают системы защиты с помощью логических и математических задач, интегрируют простенькие игры и разрабатывают все более и более продвинутые варианты. Но классическая капча с текстом остается одной из самых сбалансированных систем, хотя от ботов она уже не спасает.
Бесполезная защита
Одна из главных проблем любой капчи — ее исполнение. Боты — проблема не для пользователей, а для администраторов сайта. Перекладывать ее решение на обычных людей некорректно, тем более что при вводе очередной капчи пользователи испытывают лишь раздражение.
С развитием алгоритмов и искусственного интеллекта многие механизмы защиты стали практически бесполезными. Такая судьба постигла аудио- и видеокапчу, а также многие варианты защиты с логическими вопросами и картинками. В 2014 году сама Google продемонстрировала алгоритм, способный распознать и взломать даже максимально сложные изображения reCAPTCHA с 99,8-процентной вероятностью. Кстати, этот показатель даже выше, чем у человека.
Немало претензий и к самой reCAPTCHA. В первую очередь, необходимость вводить два слова увеличивает время выполнения задания. Не стоит забывать и о том, что пользователь помогает расшифровывать книги, тем самым выполняя работу для Google, и за эту работу ему никто не платит. Поэтому шаг поискового гиганта по изменению привычной капчи на нечто более умное и незаметное выглядит верным. Остается под вопросом лишь то, насколько умно система будет работать и точно ли облегчит жизнь рядовым пользователям.